
In a previous article on this blog, we looked at whether Linux containers suffer any performance penalty compared to physical servers — a common problem that engineers and architects in financial services need to tackle.
In this article, we’re looking at another performance-related topic: CPU architecture and how this affects application performance.
Nowadays, servers are equipped with dozens or even hundreds of CPUs, organized in hierarchies and directly connected to different internal components such as RAM banks and PCI devices. This arrangement of CPU placement within a server is known as CPU topology. In this article, I will discuss the concept of CPU topology in a server and how to optimize it to improve the performance of a multithreaded program.
Let’s start by getting familiar with some concepts
CPU architecture — history and context
First, let’s consider some context so that we can clearly understand what we are trying to achieve.
It’s very common to refer to the CPU as the unitary brain of the computer. This is certainly right but it’s a bit reductive: with modern (I mean since 20 years!) server architectures the internal complexity, hidden away behind a simple abstraction, hides considerable performance gains.
Another important aspect is the time required for the CPU to access the data located in different memory types.
The processor is extremely fast at crunching data; however, accessing the data is the main bottleneck. It is quite common for a processing unit to be in an idle state while waiting for data to arrive in its registers. The table below shows how long it takes to access information from different types of memory. Each step away from the CPU takes several orders of magnitude more time!
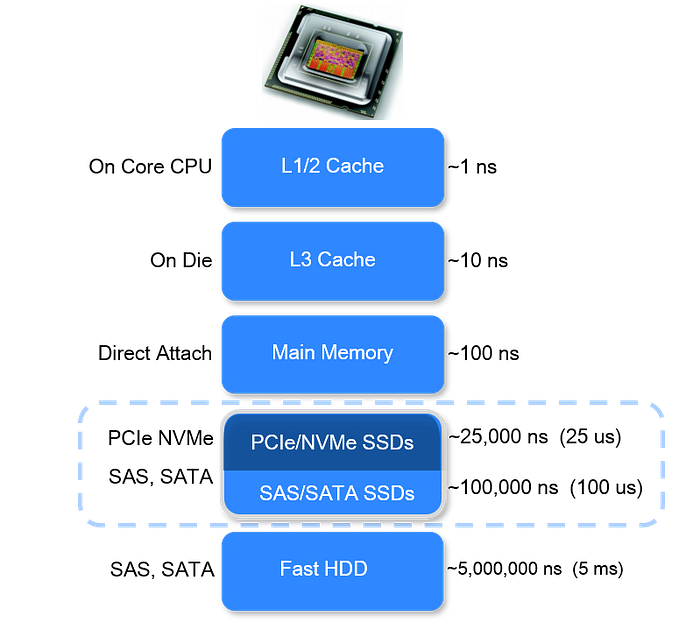
Since the beginning of the information age, this problem was known and it has generally been addressed by adding a memory between the slow device (ie disk) and the CPU. Nowadays they are referred as cache memory and we generally count tree levels of them, named L1, L2 and L3.
L1 is the closest to the CPU, and operates at the same speed (or very close) — it’s a very small amount of memory but very fast.
L2 is located on the CPU itself and it is bigger (10x) than L1.
L3 is placed outside the CPU but is sited strategically between the RAM and the CPU.
Back in the 90s, IBM compatible PC had this cache memory on the motherboard close to the CPU socket, then the Pentium Pro had it in the CPU package but it was very expensive manufacturing it and a defect in it meant discarding also the whole processor. The Pentium Pro was a commercial failure due to its high price and its successor the Pentium II had the cache on the board together with the CPU but in a different chip (under the fancy plastic cover!). Finally with the Pentium III the cache went back in the CPU since the production cost and quality had improved over time.
Now let’s examine the latest AMD CPU, each core has its own L1/L2 cache and the L3 cache is shared between multiple adjacent cores and conveniently placed in the middle.

All different Epyc series have different arrangements and you can read more about their 4th gen AMD processor architecture in their white paper.
Using Linux to understand your cache architecture
With this command on a Linux terminal, you can see how much memory has cache layer:
# lscpu|grep cache
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 32768K
The golden rule to make a multithread program run as quickly as possible with steady pace is to let all its threads run on processors which share L2 and L3 memory. Let’s work this through in a specific example.
A web application has 2 threads: one to authenticate and one to serve the client. Clearly these two threads will need to access to the same data (i.e. a session id), if this data is physically close to the CPU, the overall page will be served faster. If one thread is running on a CPU and the other on a ‘distant’ CPU (which does not share any cache with the prior), the common required data will have to travel across the server and take considerable more time.
The Linux kernel is aware of the CPU topology (see the kernel code if you don’t believe me!) and the scheduler tries its best to accommodate it.
Now let’s get on a Linux console, you can see the full CPU topology with the full output from the utility lscpu:
#lscpu -p
# CPU,Core,Socket,Node,,L1d,L1i,L2,L3
0,0,0,0,,0,0,0,0
1,1,0,0,,1,1,1,0
2,2,0,0,,2,2,2,0
3,3,0,0,,3,3,3,0
….
49,49,0,1,,49,49,49,6
50,50,0,1,,50,50,50,6
…..
64,0,0,0,,0,0,0,0
On most Linux distributions you will probably also be able to install hwloc package which provides lstopo, this utility displays the topology in a nice GUI format:
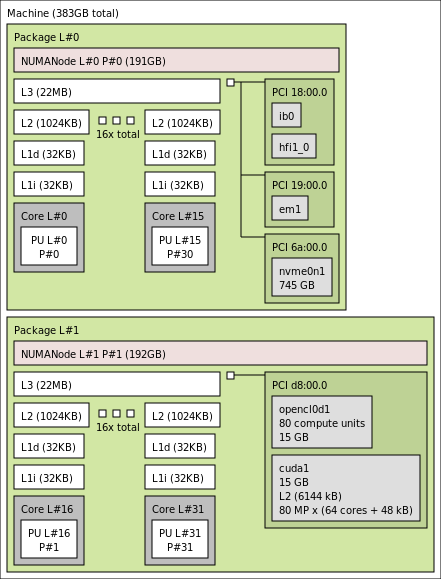
You can also interrogate every single CPU via the pseudo filesystem /sys (in this example a single CPU with 64cores and 128 threads):
# cat /sys/devices/system/cpu/cpu0/topology/die_cpus_list
0–127
# cat /sys/devices/system/cpu/cpu0/topology/core_siblings_list
0–127
# cat /sys/devices/system/cpu/cpu0/topology/package_cpus_list
0–127
# cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
0,64
(newer kernels call it core_cpus_list)
Proving the benefits of OS tuning
And now it’s show time ! I used a test suite called contextswitch and in particular the utility timectxsw which benchmarks the overhead of context switching between 2 processes.
I will compare a simple run and one pinning it to the siblings CPU:
# ./timectxsw
2000000 process context switches in 3445039218ns (1722.5ns/ctxsw)
# taskset -c 0,64 ./timectxsw
2000000 process context switches in 2399610671ns (1199.8ns/ctxsw)
The result are pretty clear, the second test run a whopping 30% faster.
I tried other cpu couples and, of course, they couldn’t run as fast.
We can use the perf utility to understand why there’s such a difference; perf will add its own overhead and for a such quick and specific utility won’t show the big increment as above… I suggest you to look only at the last line (execution time) and the cache-misses percentage : 3.6 % versus 0.12% !
Random CPU pair:
# perf stat -B -e cache-references,cache-misses,cycles,instructions,faults,migrations taskset -c 0,50 ./timectxsw
2000000 process context switches in 8803593111ns (4401.8ns/ctxsw)
Performance counter stats for 'taskset -c 0,50 ./timectxsw':
660,331,436 cache-references
23,796,026 cache-misses # 3.604 % of all cache refs
40,910,612,711 cycles
29,170,999,981 instructions # 0.71 insn per cycle
160 faults
1 migrations
8.805717047 seconds time elapsed
Pinned to the siblings CPU:
# perf stat -B -e cache-references,cache-misses,cycles,instructions,faults,migrations taskset -c 0,64 ./timectxsw
2000000 process context switches in 7977937524ns (3989.0ns/ctxsw)
Performance counter stats for 'taskset -c 0,64 ./timectxsw':
700,813,458 cache-references
849,871 cache-misses # 0.121 % of all cache refs
35,950,476,130 cycles
19,387,156,865 instructions # 0.54 insn per cycle
159 faults
1 migrations
7.979957241 seconds time elapsed
Now you may argue “Mauro, your program simply did 2 milions context switches, it’s not realistic!“.
I will show you another program to convince you it’s worth spending time tuning the OS to speed up your application.
We can have a look at this lovely c++ utility c2clat. By default it runs two threads on different processors and calculates how many clock ticks are needed for them to read each other memory, like a ping test. After all permutations between all available processors it prints a table like the one below:
[root@vmx204 ~]# taskset -c 0,1,64,65 ./c2clat
CPU 0 1 64 65
0 0 59 22 57
1 59 0 57 22
64 22 57 0 59
65 57 22 59 0
Column and rows are CPU cores, so the intersection between the column 0 and row 64 is 22, the unit is nanoseconds, this means it takes 22ns for two threads on the respective CPUs to communicate.
Instead of running of all 128 cores and generating a huge table, I pinned it to two couple of siblings 0–64 and 1–65, as you can see the lower values is only between siblings, while more than the double delay is noted between the other CPUs.
I also did the entire test and on my EPYC 9554P 64-Core Processor I noted the worse performance is 243ns, 10 times slower 🙂
Modern CPUs implement simultaneous multithreading (SMT) technology which allows two threads to run on one core (Intel calls Hyperthreading). This ‘core’ provided by SMT is commonly referred to as a logical processor (at least in BIOS terminology). If you disable SMT , the kernel won’t find any siblings and the above optimizions are evaporated, in fact the cpu count seen by the kernel is halved and lstopo will list only one CPU sharing L2 cache:
# cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
0
# lstopo-no-graphics |head
Machine (251GB total)
Package L#0
Group0 L#0
NUMANode L#0 (P#0 125GB)
L3 L#0 (32MB)
L2 L#0 (1024KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
L2 L#1 (1024KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1
PU L#1 (P#1)
I won’t report its output for brevity, but if you run c2clat accross all processors, you won’t see any latency lower than 46ns; another sign that the logical processors are really interconnected.
How Beeks helps you to take advantage of these performance benefits
In Beeks Analytics we use this locality optimization to add an extra 250k processed packets per second, which in case of multiple instances, which translates in 1 Million more packets committed to the database. And if you’re deploying your application on the Beeks cloud or in our precision engineered Proximity Cloud or Exchange Cloud solutions you know that we have dedicated system administrators and performance experts who can help you make the most of the underlying operating system, hardware, and connectivity options.
In a future article I will discuss more in depth about NUMA and PCI ‘topology’ optimization to make sure it’s all coherently organised.
Note:
For my tests I used kernel 6.5.7 but I’m confident you can achieve similar results with recent kernel (unless the changelog show work around the scheduler).




